
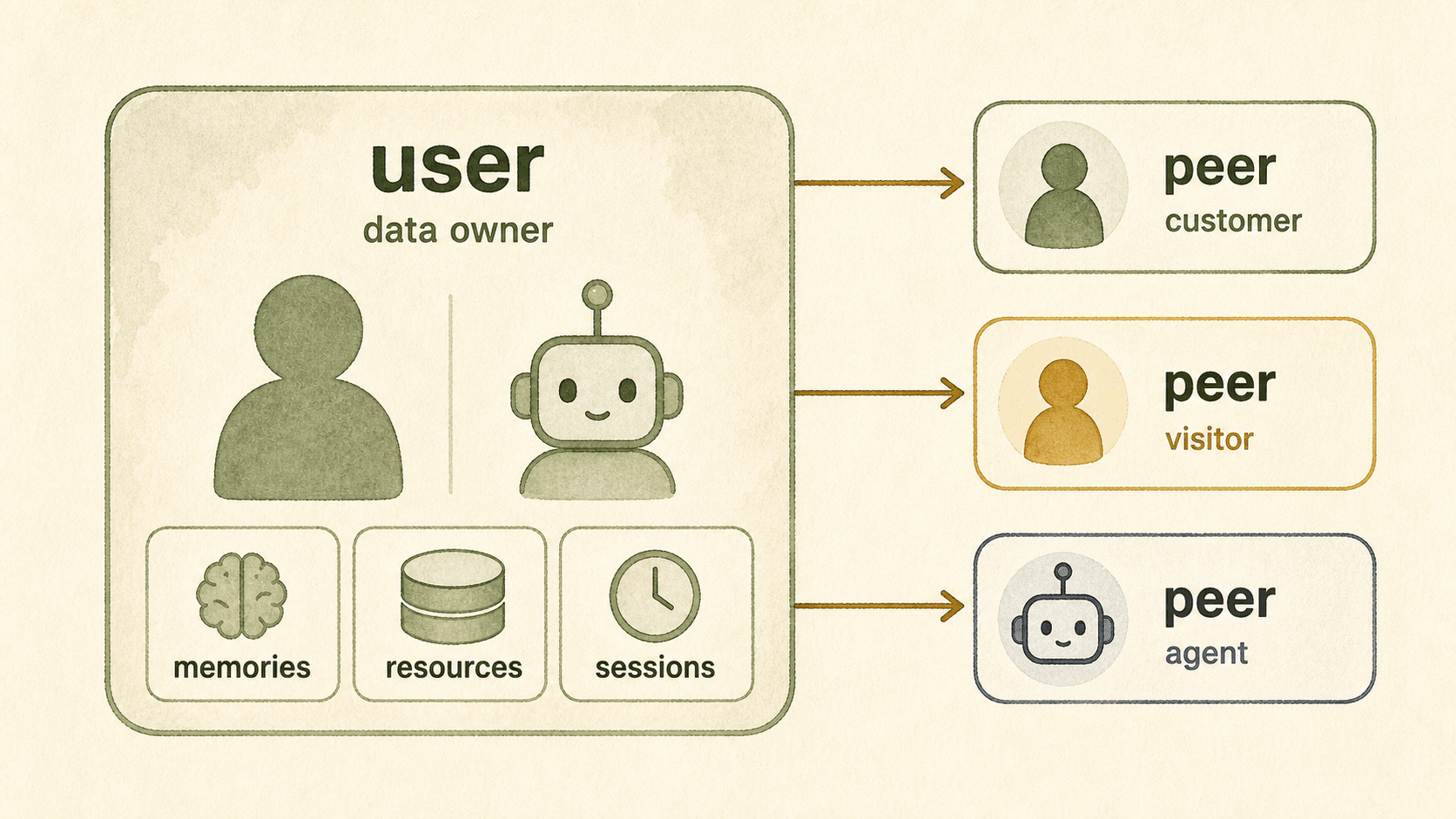
Long-term context systems first need to answer a simple ownership question: which OpenViking user owns this data space, and which object is merely interacting with it right now?
In single-user use, the answer feels obvious. Alice uses an assistant, so Alice is the data owner. Memories, resources, skills, and sessions all revolve around Alice.
Real agent applications are less tidy. A support bot may serve many customers. A bot service may talk with many group members. An IDE plugin may represent one fixed tool instance while interacting with different people, projects, and runtime agents every day.
That is why OpenViking should not treat every current speaker as an OpenViking user. In OpenViking, a user is a service-layer data subject. It may be a natural person, or it may be an agent, bot service, support desk, or fixed integration instance.
User is not necessarily a person
In OpenViking, user means the owner of a data space. That space can contain memories, private resources, installed skills, and sessions. A user can therefore be a natural person, but it can also be a service identity such as a support bot or workbench.
The analogy is close to the difference between a natural person and a legal person: both can be subjects. Here the subject is not about legal liability; it is an engineering boundary for data ownership.
A peer is the object this data subject is interacting with. In a support scenario, the service bot can be the OpenViking user while each customer becomes a peer under that user.
account = acmeuser = support-botpeer = customer-alicepeer = customer-bobHere support-bot owns the OpenViking data space. Alice and Bob are the objects it serves. The bot may need to remember Alice’s preferences and Bob’s historical issues, but Alice and Bob do not have to become first-class OpenViking authenticated users with separate user keys.
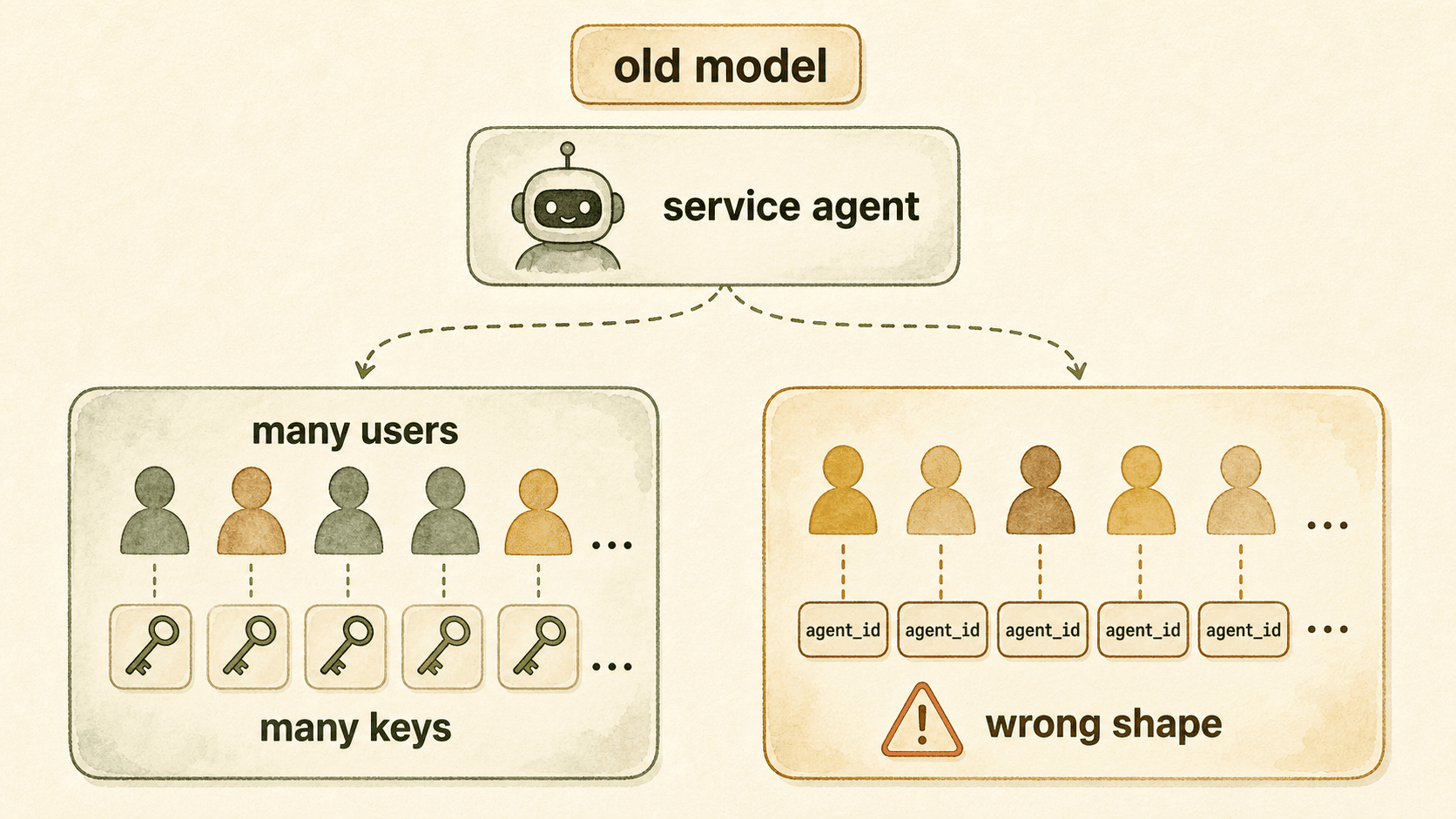
Why the old User / Agent model felt awkward
Earlier OpenViking usage was closer to an account / user / agent mental model. The user_id was the formal data identity and was usually bound by the user key. The agent_id was easier to pass as runtime context and could distinguish assistants, tools, or environments.
That worked for one person using several agents. It became awkward when one agent service needed to serve many external people or objects and persist personal memory for each of them.
| Old path | Why it hurts |
|---|---|
| Register every external object as an OpenViking user | The semantics may look clean, but every user has its own key. Platforms now have to manage registration, distribution, rotation, delegated access, and permission boundaries for objects that may only be served participants. |
| Put the external object into agent_id | It is lightweight to pass, but the shape is wrong. Customers and group members are not agents, and the data owner, interaction object, and retrieval scope become mixed together. |
The new model: user owns data, peer describes the interaction object
User / Peer turns the boundary into one simple relationship. Account remains the tenant or workspace boundary. User is the data owner inside OpenViking. Peer is an interaction object under that user.
account└── user ├── memories ├── resources ├── skills ├── sessions └── peers ├── customer-alice │ ├── memories │ └── resources └── customer-bob ├── memories └── resourcesA peer does not change the tenant, authentication identity, or user boundary. It narrows the content scope inside the current user’s data space.
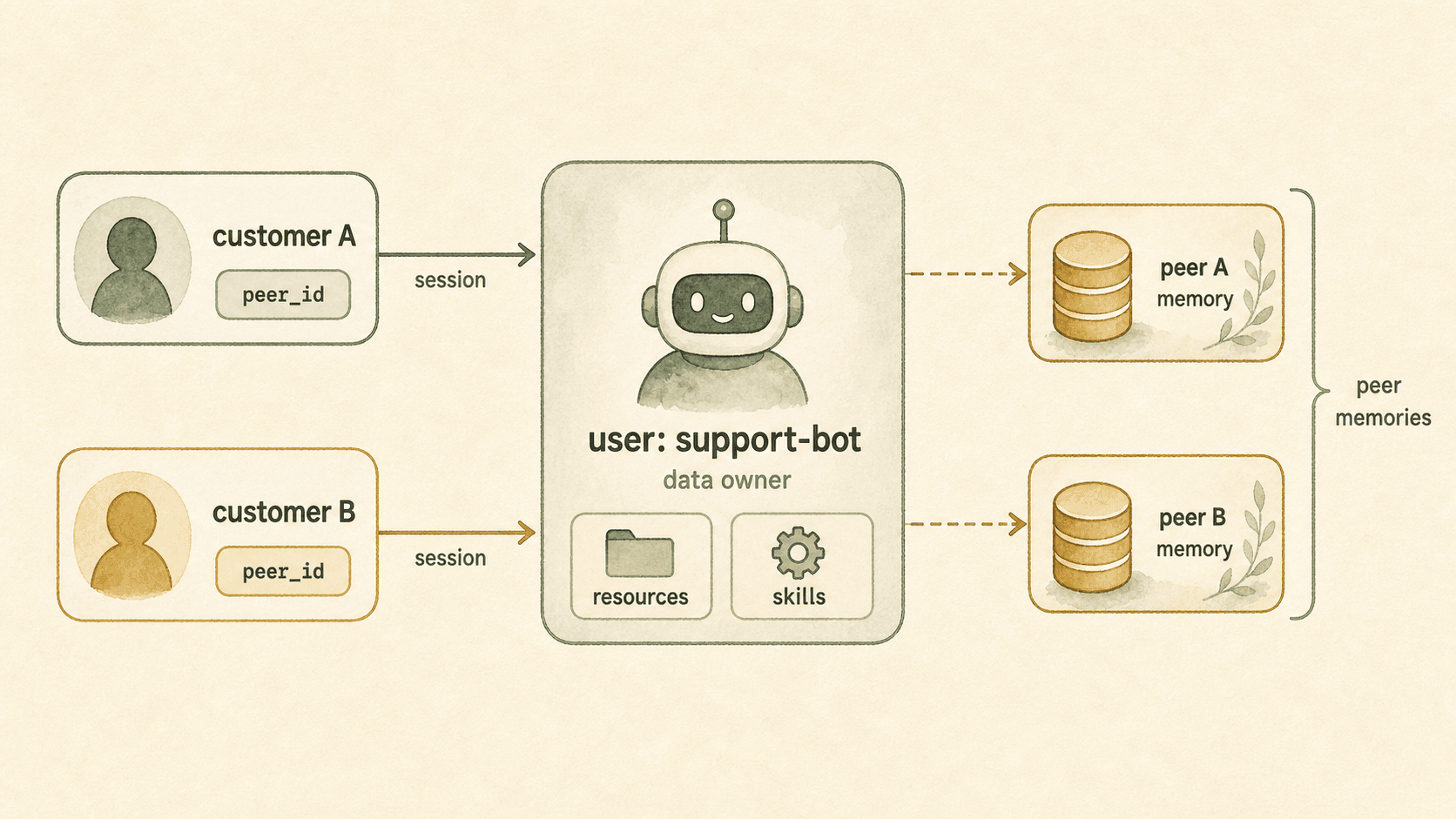
Support bot as user, customers as peers
user = support-bot support-bot/memoriessupport-bot/resourcessupport-bot/sessions support-bot/peers/customer-alice/memoriessupport-bot/peers/customer-bob/memoriesAlice’s invoice preference, contact style, and historical requests can be stored under customer-alice. Bob’s context is stored under customer-bob. Both still belong to the support-bot data owner.
A natural person can still be the user
user = alicepeer = coding-agentpeer = life-agentIf Alice owns the data space, different agents can be represented as peers under Alice. The rule is not “user must be a person” or “peer must be an agent.” The rule is: identify the data owner first, then identify the interaction object.
How developers use it
The common path has three steps: use a user key to establish the data owner, attach peer_id to session messages, and use actor_peer_id when you need a peer-restricted retrieval or filesystem view.
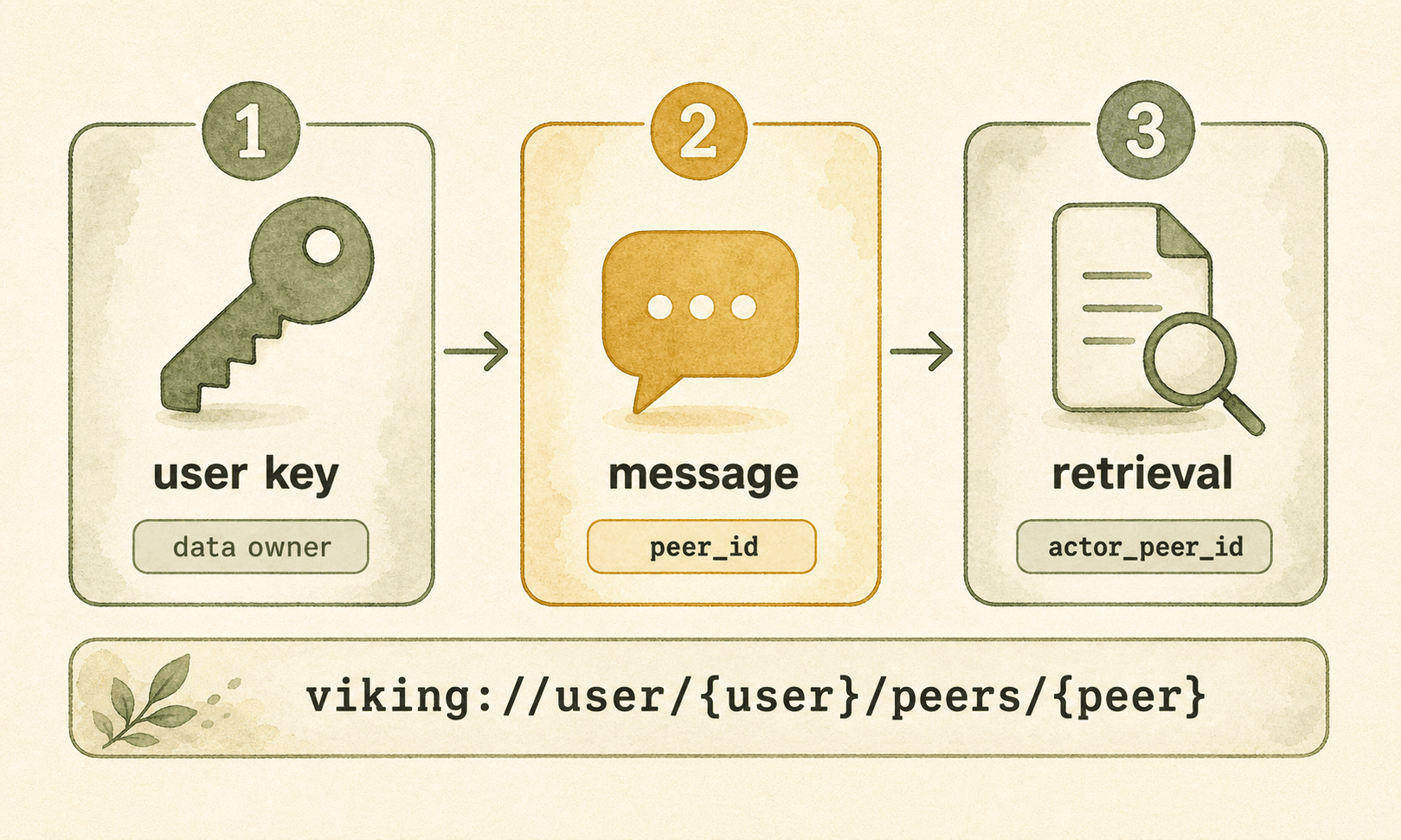
1. Use a user key to select the owner
import openviking as ov client = ov.SyncHTTPClient( url="http://localhost:1933", api_key="<support-bot-user-key>",)client.initialize()The key can belong to a natural person or to an agent service. The server resolves the current account and user from that key, and subsequent data operations happen in that user space.
2. Attach peer_id to session messages
session = client.create_session( memory_policy={ "self": {"enabled": True}, "peer": {"enabled": True}, })session_id = session["session_id"] client.add_message( session_id, role="user", content="Please issue invoices under Volcano Engine.", peer_id="customer-alice",) client.add_message( session_id, role="assistant", content="Got it. I will remember this invoice preference.", peer_id="customer-alice",) client.commit_session(session_id)The peer target is enabled explicitly through memory_policy. During commit, OpenViking can write relevant peer memory under the current user’s peer path.
viking://user/{user_id}/peers/{peer_id}/memoriesviking://user/{user_id}/peers/{peer_id}/resources3. Use actor_peer_id for a peer view
alice_view = ov.SyncHTTPClient( url="http://localhost:1933", api_key="<support-bot-user-key>", actor_peer_id="customer-alice",)alice_view.initialize() results = alice_view.find("invoice preference")actor_peer_id filters the current user’s peer collection to customer-alice. It does not authenticate the request as Alice, and it does not switch account or user.
Keep peer_id path-safe
Use a stable single path segment as peer_id. Values containing path separators are rejected.
| Good examples | Rejected shape |
|---|---|
| |
What this changes for platforms and plugins
The biggest change is that platform integrations no longer need to debate whether every external object must become an OpenViking user.
| Scenario | Recommended shape |
|---|---|
| Support bot | OpenViking user = support-bot; customers = peers. |
| Developer tool plugin | OpenViking user = a natural person or fixed tool instance; runtime speakers or agents = peers. |
| Messaging bot | OpenViking user = bot service; sender or group member = peer_id. |
- The data owner becomes more stable.
- Authentication and key management stay smaller.
- One-to-many participants can be isolated naturally.
- Retrieval and filesystem views follow the same peer filter.
- The main data path becomes the user-scoped viking://user/... space.
The takeaway
User / Peer is not just another field on a message. It separates two responsibilities that long-term context systems must keep distinct: who owns the data, and who the current interaction is with.
Once that boundary is clear, memories, resources, skills, and sessions have stable ownership and can be reused safely by agents, plugins, and platforms.